February 27, 2025
Enrich your Synthetic Users with your data. RAG tutorial.
With Retrieval-Augmented Generation (RAG), we’re effectively allowing you to upload documents—such as previous interviews, past surveys, and consumer insight reports—that you believe will add more depth and help ground your synthetic users in your own data. At a high level, RAG works by indexing the documents you provide and retrieving the most relevant pieces of information whenever the model needs them. This ensures the outputs are guided by authentic, domain-specific material. By anchoring your Synthetic Users in data that you’ve curated, you reduce the chance of receiving generic or inaccurate responses, which can sometimes occur with large language models that draw only on their built-in training data.
Keep in mind, however, that the large language models we use (we shuffle between multiple frontier models) were trained on a vast range of internet-based data spanning roughly the last 25 years. It’s possible that your uploaded documents—or at least portions of them—already exist within the model’s training set. In these cases, re-uploading the same content primarily serves to solidify trust and control in the process, rather than introduce new information. Even if the model “knows” some of the data from prior training, specifying these documents explicitly makes sure the relevant insights are prioritized. Ultimately, RAG gives you a direct way to shape the generated output with your own data, helping ensure that the synthesized findings reflect your unique context.
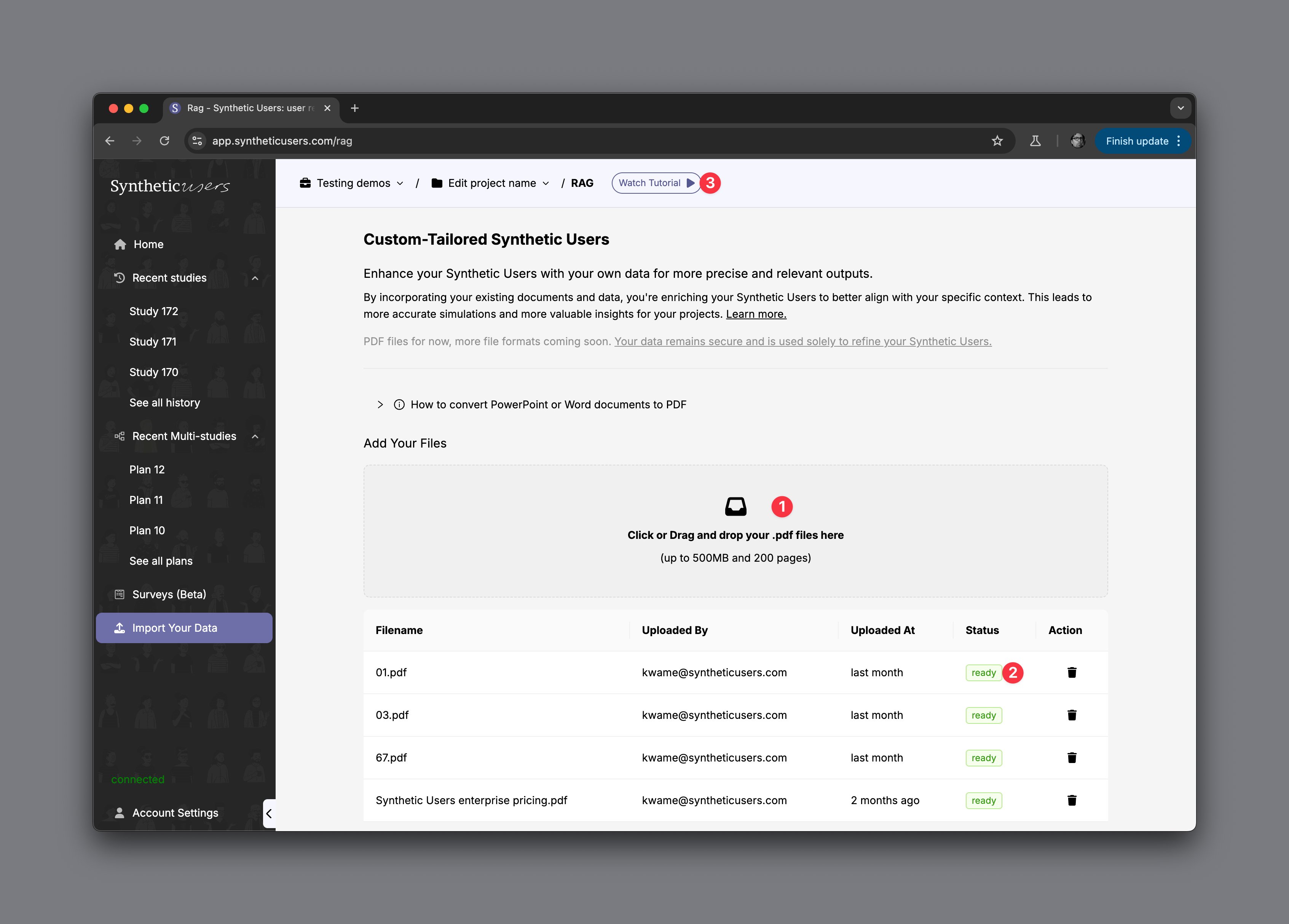
- Drag and drop any PDF into this area that you have. The constraints are it can't go over 500 megabytes or 200 pages long.
- Ensure that the status is ready. When you upload any document into our RAG framework, that document needs to be processed and made available to the Synthetic User's engine. So keep an eye on this status indicator.
- You can find a link to watch the tutorial at the very top. This is the video where we explain RAG: https://www.youtube.com/watch?v=68f-gs0pV6M&t=2s

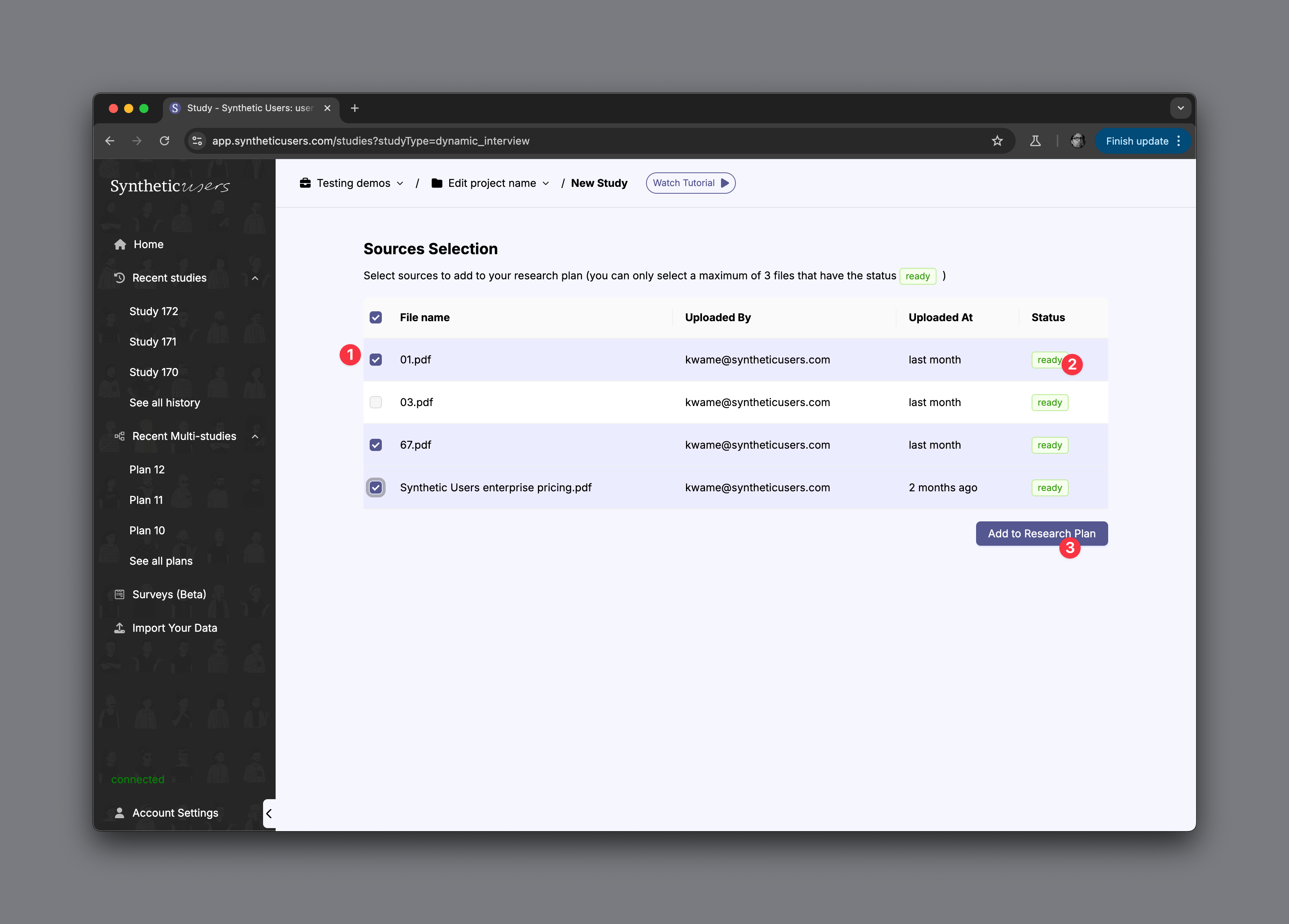
After selecting your interview type and before starting your research plan, you’ll see a screen called Sources Selection.
On this screen:
1. you can choose up to three previously uploaded documents to use as enrichment sources for your upcoming study.
2. Ensure that the status is green.
3. Press the main CTA in order to start your study.
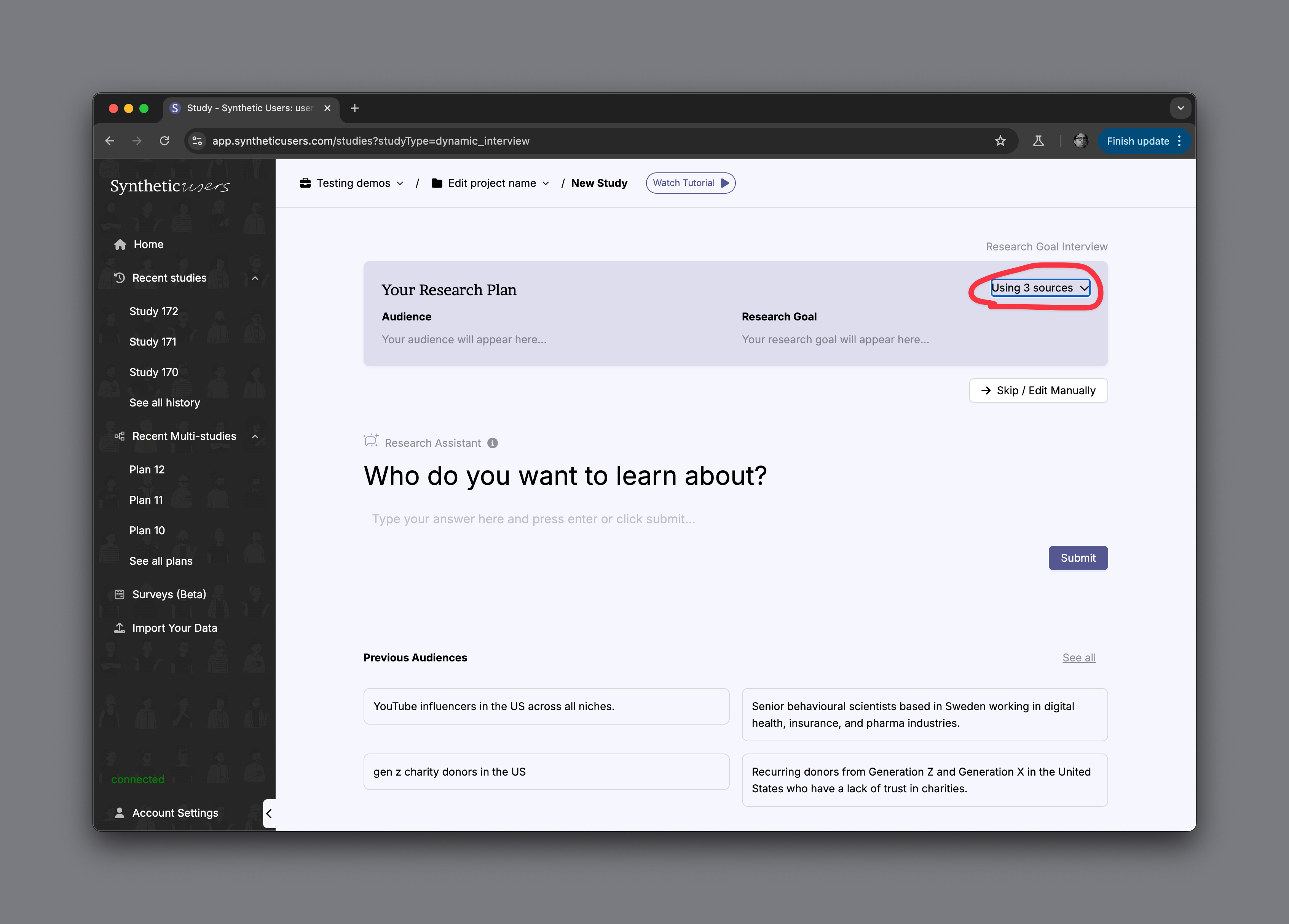
When you begin filling out your research plan, you’ll notice an indicator in the top-right corner showing that three sources are in use. Tapping this tab reveals exactly which sources are enriching your synthetic users in the study.